ChatGPT, Claude, Perplexity & Co. citano e linkano contenuti che tecnicamente possono recuperare senza problemi. Se il tuo sito è invisibile a questi bot (o fornisce solo codice vuoto), le tue possibilità di ottenere reach, trust e richieste da parte di potenziali clienti diminuiscono. In questa guida, ti mostrerò i problemi tecnici più comuni, e corrispondenti semplici controlli passo-passo,che puoi svolgere per verificare se i bot AI vedono davvero i tuoi contenuti.
Indice dei contenuti
Quali sono gli user agent AI da conoscere attualmente?
Esistono già innumerevoli user agent dei vari LLM che si aggirano su Internet. Nel marketing, ci concentriamo su quelli attualmente rilevanti.
I bot ovvero gli user agent più comuni sono attualmente (aggiornamento: settembre 2025):
| Bot AI | Per cosa viene utilizzato |
| GPTBot | Crawler ufficiale di OpenAI. Raccoglie i contenuti delle pagine in modo che l'IA possa imparare da essi e garantire la qualità. In parole povere: il contenuto viene reso utilizzabile per il modello. |
| ChatGPT User | Appare nelle sessioni in cui ChatGPT apre pagine web dal vivo. Recupera i contenuti in tempo reale, in modo che le risposte tengano conto delle informazioni attuali. |
| OAI SearchBot | Crawler per la ricerca da OpenAI. Indicizza i contenuti in modo che i siti web possano apparire nei risultati della ricerca OpenAI. Questo bot è utilizzato anche dall'Atlas Browser di OpenAI. |
| ClaudeBot | Crawler generale di Anthropic. Rende il contenuto delle pagine accessibile ai sistemi Claude, in modo che possano comprenderlo e citarlo. |
| Claude User | Utilizza le pagine viste in tempo reale durante una sessione di Claude. Obiettivo: recuperare contenuti aggiornati e utilizzarli nelle risposte. |
| PerplexityBot | Crawler ufficiale di Perplexity. Aggiunge contenuti all'indice di Perplexity in modo che possano apparire nella ricerca. |
| Perplexity User | Utilizzato per le risposte in tempo reale di Perplexity. Recupera i contenuti in modo che le citazioni e i risultati siano aggiornati. |
| Google NotebookLM | NotebookLM è uno strumento di intelligenza artificiale di Google che analizza il contenuto di documenti o siti web su richiesta dell'utente. Uno speciale bot chiamato „Google-NotebookLM“ recupera la pagina. Poiché viene attivato dall'utente, ignora i blocchi robots.txt. |
Possibili ragioni tecniche per cui i bot AI non riescono ad accedere o leggere il tuo sito
Spesso si pensa solo al design esteticamente gradevole di un sito web e meno ai requisiti tecnici per l'accesso al sito da parte dei bot AI o non AI. Google è in grado di leggere quasi tutti i siti web moderni, ma questo non vale automaticamente per i LLM come i modelli di Anthropic, X, Meta & Co. Andiamo. C'è quindi bisogno che ti informi sulle insidie tecniche più comuni.
Robots.txt
Il file robots.txt è un piccolo file di testo che viene solitamente fornito dai siti web per definire quali contenuti possono essere visitati da quali bot (ad esempio Googlebot, ma anche bot AI) e quali no.
Se blocchi alcuni user agent nel file robots.txt per accedere a certi contenuti, i bot "ben educati" come quello di Perplexity obediranno a questa regola. Tuttavia, non c'è ancora una dichiarazione ufficiale da parte di tutti i fornitori di LLM se il file viene rispettato, ma sembra che quasi tutti lo facciano (lo vedo regolarmente nel reporting di Cloudfront, ad esempio).
Tieni in mente che un bot AI bloccato che rispetta il file robots.txt non può leggere i tuoi contenuti, ovviamente, e il LLM non potrà suggerire i tuoi contenuti web ad altri utenti. A meno che non sappia già dei tuoi contenuti perché facevano parte dei dati con cui è stato allenato.
Hosting/CDN blocca i bot AI
Succede che i siti web non sono bloccati per gli user agent AI tramite il file robots.txt, ma dall'infrastruttura di hosting o CDN: Esistono numerose opzioni di blocco da parte dei provider di hosting o dei CDN (rate limiting, firewall,...). Di solito questi blocchi forniscono ai bot AI codici di stato 403/429 o errori di connessione e non potranno accedere ai tuoi contenuti.
Geoblocking
Alcuni siti web bloccano l'accesso da determinati Paesi. Questo può essere utile per motivi legali o di sicurezza. Se gli user agent AI accedono da server esteri, a volte possono quindi trovarsi bloccati.
Il contenuto importante della pagina viene caricato tramite JavaScript
Gli user agent dei LLM non eseguono JavaScript. Vedono solo l'HTML grezzo, non eventuali contenuti caricati tramite JavaScript sul tuo pc. Questo può essere un problema per i siti web "moderni" che non sono stati creati secondo le migliori pratiche SEO. Piccola nota: questo non sarebbe successo con una specialista SEO come me, per esempio 😉
Se i contenuti principali, come la navigazione e il contenuto testuale principale delle singole pagine, possono essere letti solo dopo il rendering di JavaScript, bisognerebbe contattare la persona/agenzia che ha creato il sito web per te, per trovare una soluzione. Naturalmente esistono soluzioni per questo problema, spesso anche senza dover stravolgere il codice del sito.
La pagina è bloccata dalla direttiva robots noindex o da X-Robots
Esistono due modi diversi per dire ai motori di ricerca di non salvare una pagina nel loro database (termine tecnico: indicizzazione):
- in genere per le pagine normali: <meta name="robots" content="noindex".> nel codice HTML della pagina
- per i PDF (ma è stato riscontrato anche per le pagine normali): x-robots-tag nell'intestazione della risposta HTTP
Entrambe le varianti normalmente impediscono l'inclusione negli indici di ricerca classici, come quelli di Google o Bing.
Visto che gli LLM, tuttavia, ricavano le loro informazioni principalmente dai dati di addestramento,potrebbe essere che un tag noindex impostato ora non impedisca alle informazioni del vostro sito web di apparire nei risultati di una ricerca AI.
Ma possono accedere anche alle informazioni su Google o Bing quando la ricerca web è attivata. In questi casi, è probabile che il tag noindex funzioni e possa quindi potenzialmente impedire che i tuoi contenuti vengano utilizzati per le risposte nelle chat AI. In tal caso, i tuoi contenuti non potrebbero essere trovati né citati o linkati.
Come scoprire se il tuo sito web è accessibile e leggibile per i LLM
Dopo aver descritto tutti gli elementi tecnici di prevenzione dell'AI, che possono limitare la tua visibilità nei risultati, veniamo alla parte pratica. Ora potrai scoprire se il tuo sito è accessibile e leggibile anche da ChatGPT e consorti. Per farlo, ti propongo i test più semplici possibili, ma per due check non è possibile evitare di dover installare un plugin/un software.
I bot AI vengono bloccati in robots.txt?
Apri il file robots.txt del tuo sito web, per esempio https://www.iltuosito.com/robots.txt. Se esiste un file di questo tipo, è SEMPRE accessibile sotto /robots.txt. Se non compare nulla, vuol dire che non ne hai uno. Non potrà tenere lontano niente e nessuno dai contenuti del tuo sito. In questa sezione presumo che tu abbia un file robots.txt.
Il file robots.txt può presentarsi come in questo esempio, ma può contenere righe diverse a seconda della configurazione individuale:
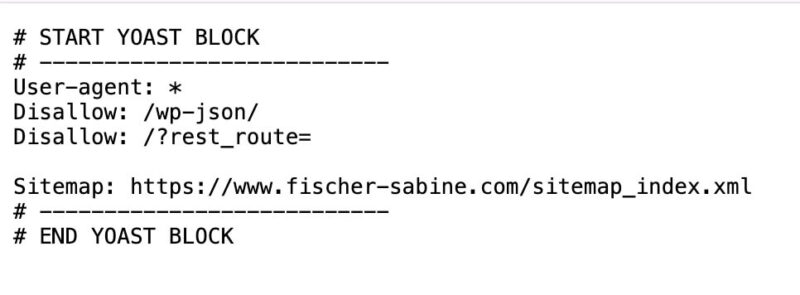
Cerca nel file i nomi dei seguenti user agent: GPTBot, ChatGPT-User, OAI-SearchBot, ClaudeBot, Claude-User, PerplexityBot, Perplexity-User. Presta attenzione alle righe "disallow": "disallow" significa che non desideri che determinati contenuti vengano consultati da determinati user agent.
Per esempio, le due righe seguenti significano che tutti gli user agent (l'asterisco sta per "tutti") hanno un disallow (=un divieto di accesso) per la cartella /wp-json/:
User-agent: *
Disallow: /wp-json/
Se non si trovano menzioni corrispondenti degli agenti utente nominati o le righe seguenti (un " User-agent: * " abbinato a "Disallow: /" significherebbe che hai bloccato l'intera pagina per tutti i bot)... :
User-agent: *
Disallow: /
... allora tutto dovrebbe essere a posto. In caso di dubbi, scrivimi.
Il tuo hosting/CDN blocca i bot AI?
Poiché i provider di hosting sono molto diversi tra loro, non è possibile fornire istruzioni generali per testare se ci sono impostazioni di blocco per gli user agent AI.
L'unica cosa che aiuta in questo caso è accedere alla piattaforma di hosting e consultare le impostazioni del server per verificare se è possibile effettuare impostazioni in relazione agli user agent AI. In caso di dubbio, è sempre una buona idea aprire un ticket di supporto e chiedere direttamente se il provider di hosting o la CDN blocca determinati user agent AI.
Se utilizzi Cloudflare, come innumerevoli altri gestori di siti web, la seguente sottosezione ti interesserà.
Controllo e monitoraggio degli accessi degli user agent AI su Cloudflare
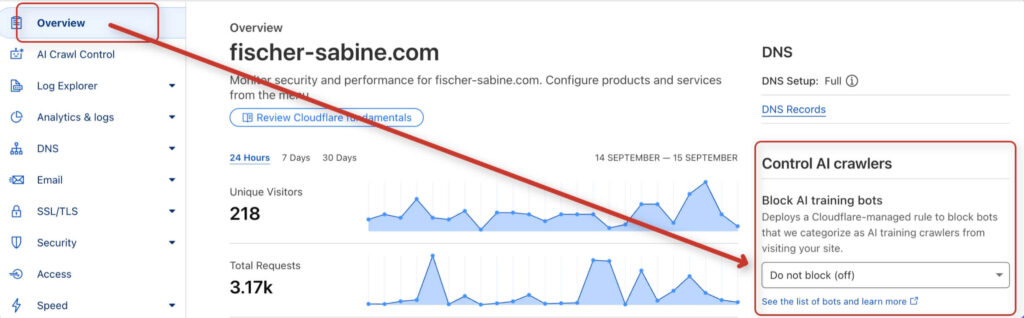
Se utilizzi la CDN di Cloudflare, vedi la scheda "Overview" e controlla se l'opzione "Block AI training bots" è attiva. In tal caso, è necessario disattivarla per non bloccare l'accesso al sito.
Nella scheda "AI Crawl Control" è inoltre possibile cercare eventuali problemi con i bot AI e visualizzare le statistiche di accesso. Qui troverai, tra l'altro, un rapporto con gli accessi dei bot nelle ultime 24 ore e informazioni se i vari bot sono riusciti ad accedere ai contenuti.
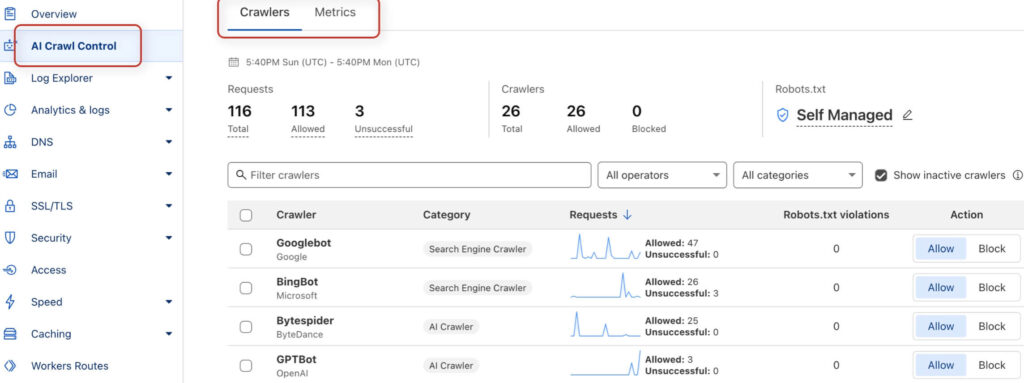
Verifica se ci sono segni di accessi non riusciti. Se capita spesso che gli accessi non vanno a buon fine, è necessario indagare sui motivi. Se noti che gli accessi perlopiù vanno sempre a buon fine, non dovrebbero esserci problemi di accesso.
Il tuo sito web può essere visitato da tutti i paesi?
Per vedere se il tuo sito web blocca l'accesso da alcuni paesi,è possibile utilizzare servizi gratuiti come "geopeeker.com" o applicazioni VPN (a pagamento) come NordVPN o Surfshark. Qui lo screenshot del mio test su geopeeker.com.
Chiama il tuo sito web da diversi Paesi. Se non dovesse essere caricato da tutti i Paesi, potrebbe essere attivo il geoblocking. Nota: da alcuni Paesi è anche possibile che il governo stesso regola l'accesso ai siti web. Come nel mio caso, da Singapore non ha potuto essere chiamato.
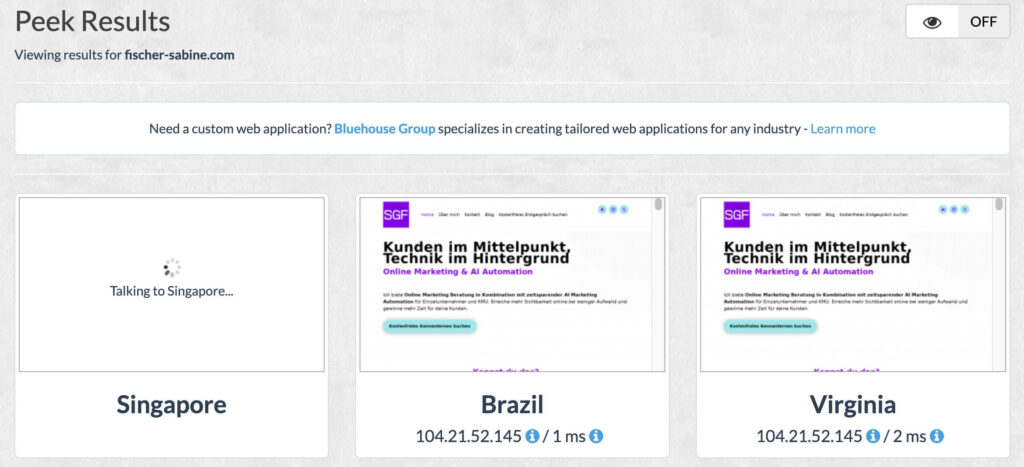
Tuttavia, il geoblocking è piuttosto raro. Alcuni siti di e-commerce lo utilizzano quando non sono autorizzati a vendere in determinati Paesi. Ma esistono anche soluzioni più eleganti.
I contenuti importanti vengono caricati solo tramite JavaScript?
Questo test è incredibilmente importante. È l'unico test di questa guida che si concentra sulla leggibilità dei contenuti da parte dei bot AI e non sugli elementi di blocco che impediscono la visualizzazione della pagina.
A questo punto, purtroppo, è necessario installare temporaneamente un browser plugin. Non preoccuparti, non si tratta di un plugin sconosciuto insicuro, ma di un plugin molto usato da SEO e sviluppatori web. Potresti anche usarlo ancora per altri test in futuro, è infatti utile per molte cose.
Il plugin si chiama "Web Developer" ed è scaricare da questo link disponibile per Chrome e Brave.
Una volta installato, fai clic sull'icona a forma di puzzle ("Estensioni") nell'angolo in alto a destra della barra del browser e aggiungi il plugin alla barra dei plugin in modo che sia disponibile per l'uso.
Per iniziare, vai sul tuo sito web.
Ora clicca sull'icona del plugin e apri la prima tab denominata "Disable" e clicca su "Disable JavaScript".

Ricarica la pagina nel browser in modo che l'impostazione diventi attiva. Ora stai guardando il sito web senza JavaScript.
Come appare il tuo sito? La navigazione, i link e soprattutto i contenuti principali funzionano ancora e sono visibili? Allora congratulazioni, è tutto a posto. Ora sai che ChatGPT e co. possono leggere i tuoi contenuti.
Ora torna al plugin, torna alla tab "Disable" e fai nuovamente clic su "Disable JavaScript" per riattivarlo.
Ricaricate la finestra del browser e il gioco è fatto. Se non si ha più bisogno del plugin, è sufficiente disinstallarlo.
Robots noindex o X-Robots bloccano l'indicizzazione dei contenuti?
Controlla per la presenza di "meta name="robots" content="noindex"" nel codice HTML del tuo sito web <meta name=’robots‘ content=’noindex‘.‘> o nel header HTTP per la presenza di "X-Robots-Tag: noindex".
Questi due termini apparentemente criptici sono due modi per segnalare ai motori di ricerca come Google, ma anche ai bot AI, che una determinata pagina o un determinato file non devono essere inclusi nell'indice di ricerca. In altre parole, questo particolare contenuto non dovrebbe essere memorizzato nei database di questi fornitori.
Entrambi possono essere attivi (a volte per errore). Tuttavia, l'uso del tag x-robots è piuttosto raro e di solito è limitato ai PDF, ma è opportuno verificare la presenza di entrambi.
Anche questo test è più rapido e approfondito con un'installazione. Questa volta con l'installazione di un software speciale che trovi tra gli attrezzi di qualsiasi specialista SEO: il Screaming Frog SEO Spider.
Non si tratta di un plug-in per il browser, ma di un software, e lo puoi scaricare da questo link qui.
Il programma offre il crawling gratuito di 500 URLe dovrebbe essere sufficiente per un sito web di piccole e medie dimensioni. In ogni caso basterà per darti una prima impressione sull'indicizzabilità delle tue pagine più importanti. Se vuoi far controllare tutto il sito web e i 500 URL non sono sufficienti, contattami semplicemente.
Dopo l'installazione, procedi come segue:
- Apri Screaming Frog e se ti può servire impostalo in lingua italiana
- Nella barra "Specificare l'URL per il crawling", inserisci l'URL della homepage del sito web (ad es. https://www.iltuosito.com).
- Fai clic su "Start". Il crawl si avvia.

- Opzionale: Per comodità puoi impostare il filtro dei contenuti in lista su "HTML", per vedere solo le tue pagine HTML e non immagini o altri file nell'elenco.
- Una volta che la crawl ha raggiunto il 100%, sposta la barra di scorrimento sotto l'elenco degli URL verso destra e cerca le due colonne "Meta Robots 1" e "X-Robots-Tag 1".
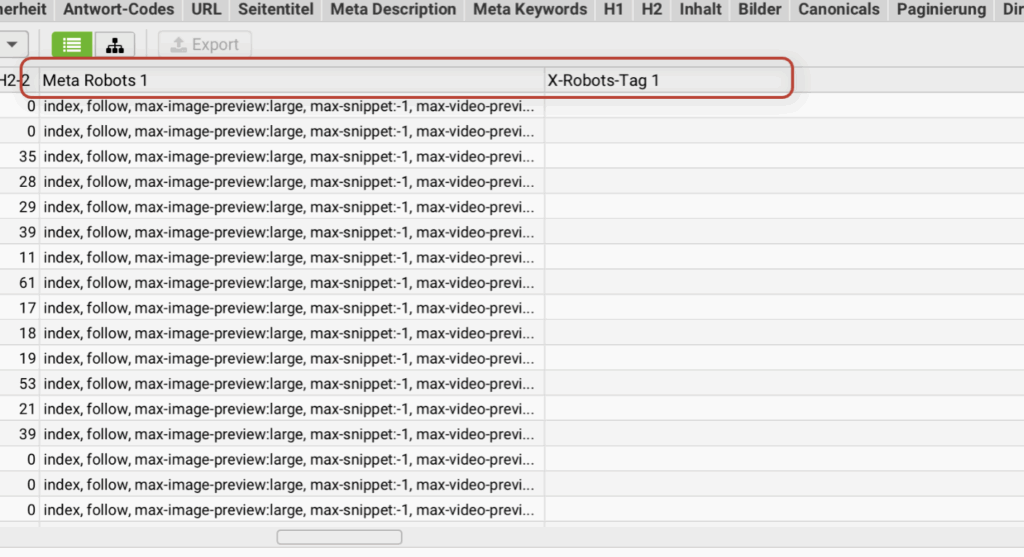
- In Meta Robots 1 dovresti sempre trovare la parola "index" (non "noindex").
- Sotto il tag 1 di X-Robots non dovrebbe esserci proprio nulla.
- Se si trovano le due etichette come descritto, è tutto a posto.
- Se vedi un "noindex" per una pagina importante sotto Meta Robots 1 o una voce sotto X-Robots-Tag 1, contatta il tuo webmaster o la persona che si occupa del sito. Altrimenti puoi contattare anche me.
- È anche possibile esportare il check in formato Excel. Puoi disinstallare il programma quando non serve più.
Il file LLMs.txt è utile per controllare i bot AI?
Forse avete sentito parlare del nuovo file che dovrebbe indicare la strada ai crawler dell'intelligenza artificiale.L'idea alla base è buona: creare un elenco Markdown snello in cui evidenziare le pagine più importanti per i modelli linguistici di grandi dimensioni, in modo che non debbano farsi strada attraverso un HTML gonfio.
Ma anche se persone intelligenti hanno messo molto cuore e anima nelle specifiche, nessuno le usa ancora. Anche John Mueller di Google ha scritto su Bluesky, che attualmente nessun sistema di intelligenza artificiale accede a llms.txt. Anche la scena dell'ottimizzazione dei motori di ricerca è d'accordo: né OpenAI né Google, né Anthropic né Meta prestano attenzione a llms.txt.
Questo significa che è una cattiva idea? No. Dimostra solo che le vostre energie sono meglio investite in basi comprovate in questo momento: struttura HTML pulita e semantica, dati schema significativi, tempi di caricamento rapidi e contenuti liberamente accessibili. Se un giorno i grandi modelli leggeranno llms.txt, potrete sempre aggiornarvi.
Cosa fare se scopro problemi durante il test?
Se i tuoi test mostrano un blocco o non sei sicuro/a, sono qui per te:
Insieme verifichiamo come ChatGPT/Claude/Perplexity vede il tuo sito e correggiamo gli errori.
Se hai a disposizione uno sviluppatore che ha creato il sito o qualcuno che lo gestisce, riceverà da me consigli precisi su come risolvere gli errori di blocco dei bot.
Una volta corretti gli errori, i vostri contenuti saranno finalmente leggibili per i bot AI. Ora nulla vi impedisce di lavorare sulla vostra visibilità nella ricerca AI!
FAQ
Perché Google sa leggere i miei contenuti, ma i LLM no?
La causa può essere in numerose impostazioni tecniche che consentono l'accesso al tuo sito web a Google, ma non ai bot AI di ChatGPT & Co. Può anche essere che il contenuto principale della pagina sia leggibile solo con il rendering di JavaScript. C'è da ricordarsi sempre che i bot LLM non sono in grado di interpretare JavaScript.
Perché i LLM non possono eseguire il rendering di JavaScript?
I LLM non sono progettati principalmente per la ricerca sul web, ma la offrono solo come opzione. Si può presumere che, a differenza di Google, non si concentrino sulla capacità di comprendere i contenuti JavaScript.
Il marketing online sta cambiando completamente! Ti adatti o ti arrendi?
Se sei tra coloro che vogliono avere successo online in futuro, clicca sul pulsante qui sotto.
Prenota la tua consulenza con me