ChatGPT, Claude, Perplexity & Co. zitieren und verlinken Inhalte, die sie technisch problemlos abrufen können. Wenn deine Seite für diese Bots unsichtbar ist (oder nur leeren Code liefert), sinkt deine Chance auf Reichweite, Vertrauen und Anfragen. In diesem Leitfaden zeige ich dir die häufigsten technischen Fallstricke und einfache Schritt-für-Schritt-Checks, mit denen du prüfst, ob KI-Bots deine Inhalte wirklich sehen.
Inhaltsverzeichnis
Welche KI-User-Agents gibt es momentan?
Es gibt mittlerweile schon unzählige KI-User-Agents, die durchs Internet ziehen. Im Marketing konzentrieren wir uns auf die, die wirklich relevant sind und konkret genutzt werden.
Gängige Bots bzw. User-Agents sind zurzeit (Stand September 2025):
| KI Bot | Wofür genutzt |
| GPTBot | Offizieller Crawler von OpenAI. Sammelt Seiteninhalte, damit die KI daraus lernt und Qualität sichert. Vereinfacht gesagt: Inhalte werden für das Modell nutzbar gemacht. |
| ChatGPT User | Erscheint bei Sitzungen, in denen ChatGPT live Webseiten öffnet. Ruft Inhalte in Echtzeit ab, damit Antworten aktuelle Infos berücksichtigen. |
| OAI SearchBot | Crawler für die Suche von OpenAI. Indexiert Inhalte, damit Webseiten in Ergebnissen der OpenAI Suche auftauchen können. Dieser Bot wird auch von OpenAIs Atlas Browser verwendet. |
| ClaudeBot | Allgemeiner Crawler von Anthropic. Macht Seiteninhalte für Claude Systeme zugänglich, damit diese sie verstehen und zitieren können. |
| Claude User | Nutzt Seitenaufrufe in Echtzeit während einer Claude Sitzung. Ziel: Inhalte aktuell abrufen und in Antworten nutzen. |
| PerplexityBot | Offizieller Crawler von Perplexity. Nimmt Inhalte in den Perplexity Index auf, damit sie in der Suche erscheinen können. |
| Perplexity User | Wird bei Antworten von Perplexity in Echtzeit genutzt. Ruft Inhalte ab, damit Zitate und Ergebnisse aktuell sind. |
| Google-NotebookLM | NotebookLM ist ein KI-Tool von Google, das Inhalte aus Dokumenten oder Webseiten auf Nutzeranfrage analysiert. Dabei ruft ein spezieller Bot namens „Google-NotebookLM“ die Seite ab. Da er vom Nutzer ausgelöst wird, ignoriert er robots.txt Sperren. |
Mögliche technische Ursachen, warum KI-Bots deine Seite nicht konsultieren können
Oft wird nur an die ästhetisch ansprechende Gestaltung einer Website gedacht und weniger an die Erfüllung der technischen Voraussetzungen für die Konsultierbarkeit der Seite seitens KI-Bots. Google kann mittlerweile mit vielen modernen Webseiten umgehen, nicht jedoch LLMs wie die Modelle von Anthropic, X, Meta & Co. Auf geht’s: hier kommen die häufigsten technischen Fallstricke.
Robots.txt
Die robots.txt Datei ist eine kleine Textdatei, die normalerweise von Websites bereitgestellt wird, um zu regeln, welche Inhalte von welchen Bots (z.B. Googlebot, aber auch KI-Bots) besucht werden dürfen und welche nicht.
Wenn du bestimmte User-Agents in der robots.txt Datei blockierst, halten sich „wohlerzogene“ Bots wie der von Perplexity daran und besuchen deine blockierten Inhalte nicht. Von vielen gibt es allerdings noch keine offizielle Aussage, ob die Datei beachtet wird, allerdings sieht es so aus, als würden es fast alle tun (sehe ich z.B. regelmäßig im Cloudfront Reporting).
Ein ausgesperrter KI-Bot, der robots.txt beachtet, kann natürlich auch dann deine Inhalte nicht lesen und deine Website auch nicht anderen Nutzern vorschlagen.
Hosting/CDN sperrt KI-Bots
Viele Seiten sind nicht wegen robots.txt, sondern in der Infrastruktur für KI-User-Agents geblockt: Blockiermöglichkeiten seitens des Hostinganbieters oder CDNs sind zahlreich (Rate Limiting, Firewall,…) und liefern dem KI-Bot in der Regel dann 403/429 Status Codes oder Verbindungsfehler und er kann nicht auf deine Inhalte zugreifen.
Geoblocking
Manche Webseiten blockieren Zugriffe aus bestimmten Ländern. Das kann aus rechtlichen oder Sicherheitsgründen sinnvoll sein. Wenn KI-User-Agents aber von Servern außerhalb deines Zielgebiets zugreifen, bleiben sie ausgesperrt.
Wichtige Seiteninhalte werden via JavaScript nachgeladen
KI-Crawler führen kein JavaScript aus. Sie sehen lediglich das Roh-HTML, nicht das, was erst nachträglich auf deinem PC gerendert wird. Das ist ein Problem für „moderne“ Websites, die nicht nach SEO Best Practices erstellt wurden. Kleine Anmerkung: mit einem SEO-Spezialisten wie mir wäre das zum Beispiel nicht passiert 😉
Wenn deine Hauptinhalte, wie z.B. die Seitennavigation und die eigentlichen Textinhalte der einzelnen Seiten nur nach JavaScript Rendering lesbar sind, solltest du die Person/Agentur kontaktieren, die dir die Website erstellt hat, um entsprechend Änderungen vorzunehmen. Lösungen hierfür gibt es natürlich, im besten Fall ohne die Seite neu bauen zu müssen.
Seite ist per noindex (Metatag) oder X-Robots-Tag gesperrt
Es gibt zwei verschiedene Arten, Suchmaschinen mitzuteilen, eine Seite nicht in ihrer Datenbank zu speichern (Fachwort: indexieren):
- generell für normale Seiten: <meta name=“robots“ content=“noindex“> im HTML Code der Seite
- für PDFs (aber auch schon für normale Seiten gesehen): x-robots-tag im HTTP-Antwortheader
Beide Varianten verhindern normalerweise die Aufnahme in klassische Suchindizes wie die von Google oder Bing.
Da LLMs allerdings ihre Informationen in erster Linie aus Trainingsdaten haben, könnte es sein, dass ein jetzt gesetztes noindex Tag nicht verhindert, dass die Informationen deiner Webseite in KI-Ergebnissen auftauchen.
Sie greifen aber auch bei eingeschalteter Websuche gerne auf Informationen aus Google oder Bing zurück oder besuchen selbst auf Nutzeranfrage eine bestimmte Webseite. In diesen Fällen ist es wahrscheinlich, dass das noindex Tag wirkt und daher potenziell verhindern könnte, dass deine Inhalte für KI-Antworten herangezogen werden. Und deine Inhalte nicht zitiert und nicht verlinkt.
So findest du heraus, ob deine Seite für KI-Bots lesbar ist
Nach all den beschriebenen technischen KI-Verhinderern, die deine Sichtbarkeit in den Resultaten einschränken können, kommen wir zum praktischen Teil. Jetzt kannst du herausfinden, ob deine Seite für KI-Bots zugänglich und lesbar ist. Dazu habe ich auf möglichst einfache Tests gesetzt, manchmal lässt sich aber nicht verhindern, doch ein Plugin kurzfristig installieren zu müssen.
KI Bots in der robots.txt ausgesperrt?
Öffne die robots.txt Datei deiner Website, z.b. https://deinedomain.com/robots.txt. Wenn du eine solche Datei hast, ist sie IMMER unter /robots.txt erreichbar. Wenn dort nichts kommt, hast du keine. Die kann dann auch nichts und niemanden von deinen Seiteninhalten fernhalten. Ich gehe in diesem Abschnitt davon aus, dass du eine hast.
Die robots.txt sieht beispielhaft so aus, kann aber ganz nach individueller Konfiguration unterschiedliche Zeilen enthalten:
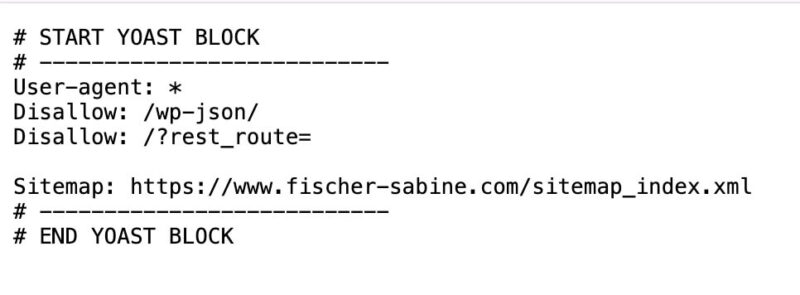
Suche in der Datei nach Einträgen für die folgenden User-Agents: GPTBot, ChatGPT-User, OAI-SearchBot, ClaudeBot, Claude-User, PerplexityBot, Perplexity-User. Achte auf Disallow-Zeilen: „disallow“ heißt, dass du einem bestimmten User-Agent bestimmte Inhalte nicht freigeben möchtest.
Zum Beispiel die folgenden zwei Zeilen bedeuten, dass alle User-Agents (das Sternchen steht für „alle“) ein disallow (=ein Zugriffsverbot) auf den Ordner /wp-json/ haben:
User-agent: *
Disallow: /wp-json/
Findest du keine entsprechenden Erwähnungen der genannten User-Agents und auch nicht die folgenden Zeilen (ein “ User-agent: * “ gepaart mit „Disallow: /“ würde bedeuten, du hast die komplette Seite für alle Bots gesperrt)… :
User-agent: *
Disallow: /
… dann sollte alles in Ordnung sein. Im Zweifel schreibe mir einfach.
Blockt dein Hosting/CDN die KI-Bots?
Da Hosting-Anbieter sehr unterschiedlich sind, kann es hier keine allgemein gültige Anleitung geben.
Hier hilft eigentlich nur: in die Hosting-Plattform einloggen und in den Servereinstellungen nachsehen, ob im Bezug auf KI-User-Agents Einstellungen vorgenommen werden können. Im Zweifel ist es immer gut, ein Supportticket aufzumachen und direkt nachzufragen, ob der Hostinganbieter gewisse KI-Bots sperrt.
Nutzt du zufällig Cloudflare, wie unzählige andere Seitenbetreiber, dann ist der folgende Unterabsatz für dich interessant.
KI-Bot-Zugangssteuerung und -Überwachung auf Cloudflare
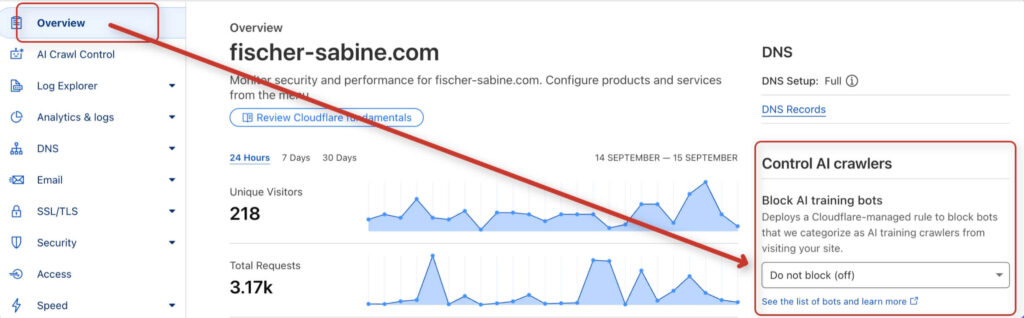
Nutzt du das CDN von Cloudflare, sieh im Tab „Overview“ nach, ob „Block AI Training Bots“ aktiv ist. Wenn ja, dann solltest du es ausschalten, damit du keine Zugriffe auf deine Seite sperrst.
Im Tab „AI Crawl Control“ kannst du auch nach Problemen forschen und Zugriffsdaten ansehen. Hier findest du unter anderem einen Report mit Botzugängen der letzten 24 Stunden sowie Informationen darüber, ob der Bot tatsächlich Zugriff bekommen hat.
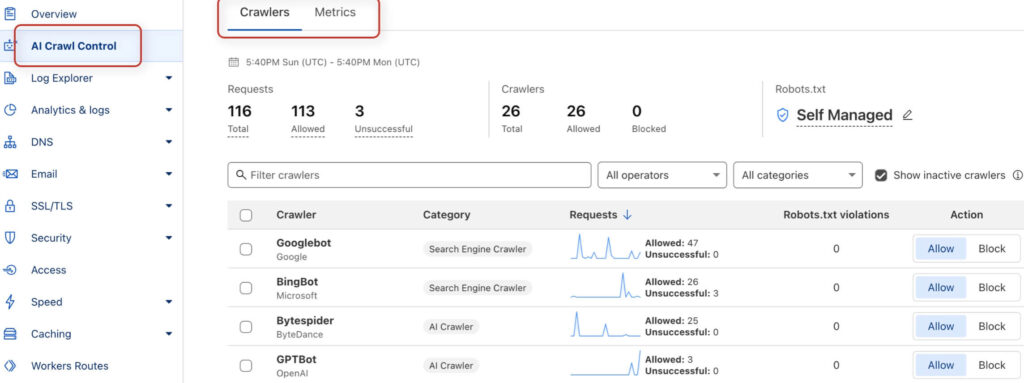
Sieh dir an, ob du Hinweise auf nicht gelungene Zugriffe finden kannst. Bei häufig missglückten Zugriffen müsste nach den Gründen geforscht werden. Wenn du siehst, dass die Abrufe erfolgreich waren, ist zugangstechnisch alles in Ordnung.
Kann deine Website von allen Ländern aus besucht werden?
Um zu sehen, ob deine Seite Zugriffe aus bestimmten Ländern blockiert, kannst du kostenlose Dienste wie „geopeeker.com“ oder (kostenpflichtige) VPN-Apps wie NordVPN oder Surfshark nutzen.
Rufe deine Seite damit aus verschiedenen Ländern auf. Wenn sie an manchen Orten nicht lädt, könnte Geo-Blocking aktiv sein.
Geoblocking kommt allerdings eher selten vor. Manche E-Commerce Seiten verwenden es, wenn sie in bestimmten Ländern nicht verkaufen dürfen. Aber auch dafür gibt es schon elegantere Lösungen.
Sind wichtige Inhalte nur per JavaScript sichtbar?
Dieser Test ist unheimlich wichtig. Es ist der einzige Test in diesem Guide, der sich auf die Lesbarkeit deines Contents seitens der KI-Bots konzentriert, und nicht auf blockierende Elemente die den Seitenaufruf verhindern.
An dieser Stelle ist es leider notwendig, kurz ein Browser-Plugin zu installieren. Keine Angst, es ist kein unsicheres 0815 Plugin, sondern DAS Plugin, das von SEOs und Web Developern genutzt wird. Eventuell kannst du es in Zukunft vielleicht sogar noch für andere Tests brauchen.
Das Plugin heißt „Web Developer“ und ist unter diesem Link für Chrome und Brave verfügbar.
Einmal installiert, klicke in der Browserleiste oben rechts auf das Puzzleteilsymbol („Erweiterungen“) und pinne das Plugin in deine Pluginleiste, damit du es für die Nutzung verfügbar hast.
Rufe nun erst einmal deine Webseite auf.
Klicke nun auf das Icon des Plugins und rufe den ersten Tab namens „Disable“ auf und klicke auf „disable JavaScript“.

Lade die Seite im Browser neu, damit die Einstellung aktiv wird. Du siehst nun deine Webseite ohne JavaScript.
Wie erscheint deine Webseite? Funktionieren die Navigation, die Links und vor allem die Hauptinhalte noch und sind sichtbar? Dann Glückwunsch, es ist alles okay. Nun weißt du, dass ChatGPT und Co. deine Inhalte lesen können.
Gehe nun wieder in das Plugin, Tab „Disable“, und klicke nochmals auf „disable JavaScript“, um es wieder zu aktivieren.
Lade das Browserfenster wieder neu, und fertig. Wenn du das Plugin nicht mehr weiter brauchst, deinstalliere es einfach.
Blockieren noindex oder X-Robots-Tag deine Sichtbarkeit?
Prüfe im Quelltext nach <meta name=’robots‘ content=’noindex‘> oder in den HTTP-Headern nach X-Robots-Tag: noindex.
Diese beiden kryptisch anmutenden Begriffe sind zwei Möglichkeiten, um Suchmaschinen wie Google, aber auch KI-Bots zu signalisieren, dass eine bestimmte Seite oder Datei nicht in den Suchindex aufgenommen werden soll. In anderen Worten, dass diese bestimmten Inhalte nicht in den Datenbanken dieser Anbieter gespeichert werden sollen.
Beide können (auch manchmal aus Versehen) aktiv sein. Der Gebrauch des x-robots Tags ist aber eher selten und beschränkt sich meist auf PDFs. Wir sollten aber auf beide testen.
Dieser Test geht leider auch wieder am schnellsten und gründlichsten mit der Installation eines speziellen Tools, das man im SEO so sicher findet wie das Amen in der Kirche: Dem Screaming Frog SEO Spider.
Es ist kein Browser-Plugin, sondern ein Programm, und man kann es unter diesem Link downloaden.
Das Programm crawlt kostenlos 500 URLs, sollte also für alle kleinen bis mittleren Webseiten ausreichen. Es reicht auf jeden Fall, um dir einen Eindruck über die Indexierbarkeit deiner wichtigsten Seiten zu machen. Falls du deine ganze Website geprüft haben willst und die 500 URLs nicht ausreichen, kontaktiere mich gerne.
Nach der Installation gehst du folgendermaßen vor:
- Programm öffnen
- Im Fenster „URL zum Crawlen angeben“ schreibst du die URL der Homepage deiner Website (z.B. https://www.meinedomain.com)
- Klicke auf „Start“. Der Crawl startet nun.

- Der Übersichtlichkeit halber setze den Filter auf „HTML“, um nur deine HTML Seiten und keine Bilder und sonstigen Dateien in der Liste zu sehen.
- Ist der Crawl beendet und steht auf 100%, verschiebe den Scrollriegel unter deiner URL-Liste nach rechts und suche nach den beiden Spalten „Meta Robots 1“ und „X-Robots-Tag 1“
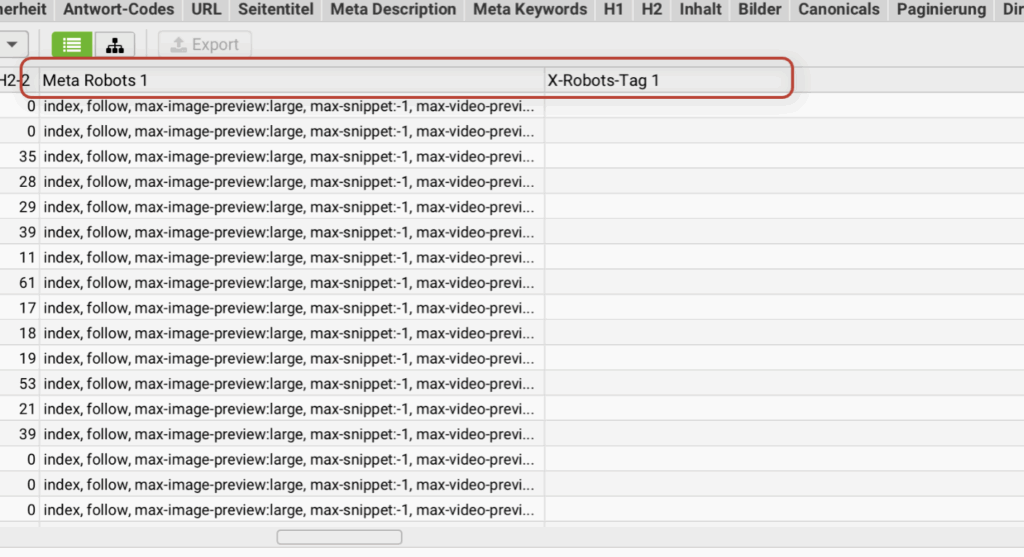
- Unter Meta Robots 1 solltest du in den Einträgen stets das Wort „index“ finden (nicht „noindex“).
- Unter X-Robots-Tag 1 sollte einfach gar nichts stehen.
- Findest du die beiden Tags so vor wie beschrieben, ist alles okay.
- Findest du für eine wichtige Seite ein „noindex“ unter Meta Robots 1 oder einen Eintrag unter X-Robots-Tag 1, dann kontaktiere deinen Webmaster oder eben die Person, die sich um die Webseite kümmert. Andernfalls kannst du auch mich kontaktieren.
- Du kannst dir den Check auch als Excel exportieren und das Programm dann löschen wenn du es nicht mehr benötigst.
Nützt die Datei LLMs.txt der Kontrolle der KI-Bots?
Vielleicht hast du schon von der neuen Datei gehört, die AI‑Crawlern den Weg weisen soll. Die Idee dahinter klingt gut: Eine schlanke Markdown‑Liste anlegen, in der du deine wichtigsten Seiten für große Sprachmodelle hervorhebst, damit diese sich nicht durch aufgeblähtes HTML kämpfen müssen.
Aber auch wenn clevere Menschen viel Herzblut in die Spezifikation gesteckt haben: noch nutzt sie niemand. Selbst Googles John Mueller schrieb auf Bluesky, dass aktuell kein KI‑System auf llms.txt zugreift. Auch in der Suchmaschinenoptimierungs-Szene ist man sich einig: Weder OpenAI noch Google, Anthropic oder Meta beachten llms.txt.
Heißt das, dass die Idee schlecht ist? Nein! Es zeigt nur, dass du deine Energie besser im Moment in bewährte Basics investierst: saubere, semantische HTML‑Struktur, aussagekräftige Schema‑Daten, schnelle Ladezeiten und frei zugängliche Inhalte. Wenn die großen Modelle eines Tages llms.txt lesen, kannst du immer noch nachrüsten.
Was tun, wenn du während dem Test Probleme entdeckt hast?
Wenn deine Tests einen Blocker zeigen oder du unsicher bist, bin ich für dich da:
Wir prüfen zusammen, wie ChatGPT/Claude/Perplexity deine Seite sehen und beheben die Fehler.
Solltest du einen Entwickler zur Hand haben, der die Seite erstellt hat oder sich darum kümmert, bekommt er/sie von mir genaue Empfehlungen zur Behebung der Bot-blockenden Fehler.
Deine Inhalte werden nach der Behebung der Fehler endlich für KI-Bots lesbar. Damit steht der Arbeit an deiner Sichtbarkeit in der KI-Suche nichts mehr im Weg!
FAQ
Warum versteht Google meine Inhalte, aber die KI findet sie nicht?
Das kann an vielen technischen Einstellungen liegen, die den Zugang zu deiner Website zwar für Google erlauben, jedoch nicht für KI-Bots wie ChatGPT & Co. Es kann auch sein, dass die Hauptinhalte der Seite lediglich mit JavaScript Rendering lesbar sind. LLM-Bots können aber kein JavaScript interpretieren.
Warum können LLMs kein JavaScript rendern?
LLMs sind nicht hauptsächlich für die Websuche konstruiert, sondern bieten sie nur als eine Option an. Es kann vermutet werden, dass sie im Gegensatz zu Google daher keinen Fokus auf die Fähigkeit haben, JavaScript Inhalte zu verstehen.
Online Marketing ändert sich gerade komplett! Ziehst du mit oder gibst du auf?
Gehörst du zu denen, die auch in Zukunft noch online Erfolg haben wollen, dann klick unten auf den Button.
Buche dein Beratungsgespräch mit mir